HPC 2010
High Performance Computing, GRIDS and clouds
An International
Advanced Workshop
Final Programme
|
|
International Programme Committee |
|||||||||||||||||||||||||||||||||||||||||||||||||||||
Organizing Committee
|
||||||||||||||||||||||||||||||||||||||||||||||||||||||
Sponsors
|
MICROSOFT |
|
|
|
|
|
|
|
|
|
|
|
AMD |
|
|
|
BULL |
|
|
|
|
|
|
|
HEWLETT PACKARD |
|
|
|
|
|
|
|
IBM |
|
|
|
|
|
|
|
MELLANOX
TECHNOLOGIES |
|
|
|
|
|
|
|
T-PLATFORMS |
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Amazon Web
Services |
|
|
|
|
|
|
|
CLUSTERVISION |
|
|
|
|
|
|
|
CRS4 Center for Advanced
Studies, Research and Development in |
|
|
|
|
|
|
|
ENEA - Italian
National Agency for New Technologies, Energy and the Environment |
|
|
|
|
|
|
|
EUINDIAGRID |
|
|
|
|
|
|
|
Harvard
Biomedical HPC |
|
|
|
|
|
|
|
HPC Advisory
Council |
|
|
|
|
|
|
|
IEEE Computer
Society |
|
|
|
|
|
|
|
Inside HPC |
|
|
|
|
|
|
|
INSTITUTE FOR
THEORETICAL COMPUTER SCIENCE - |
|
|
|
|
|
|
|
INTEL |
|
|
|
|
|
|
|
JUELICH SUPERCOMPUTING
CENTER, Germany |
|
|
|
|
|
|
|
KISTI - |
|
|
|
|
|
|
|
NEC |
|
|
|
|
|
|
|
NICE |
|
|
|
|
|
|
|
Platform
Computing |
|
|
|
|
|
|
|
SCHOOL of
COMPUTER SCIENCE and |
|
|
|
|
|
|
|
TABOR
COMMUNICATIONS – HPC Wire |
|
|
|
|
|
|
|
T-Systems |
|
|
|
|
|
|
|
|
|























|
Free Subscriptions! Stay
up-to-date with the latest news for supercomputing professionals. Subscribe
to HPCwire today and gain access to peer
discussions, premium content, and HPC industry resource tools including
market trends, career placement, and live coverage of major high performance
computing events. |
|
insideHPC.com is the web's leading source
for up-to-the-minute news, commentary, exclusive features and analysis about
everything HPC with an average readership of 1.5 million page views per
month. If your organization wants to reach the global community of
supercomputing center managers, HPC thought
leaders, senior corporate executives, program managers, and HPC
practitioners, ranging from computational scientists to system
administrators, then you’ll want to turn to insideHPC. Too busy to keep up? Subscribe to the daily email updates, RSS news
feed, or even follow us on Twitter. As a service to the HPC community, there
is no cost to subscribe to insideHPC. |
|
Free Amazon Web Service
credits for all HPC 2010 delegates Amazon is very pleased to be able
to donate $100 in service credits to all HPC 2010 delegates, which will be
delivered via email. Since early 2006, Amazon Web Services (AWS) has provided
companies of all sizes with an infrastructure web services platform in the
cloud. With AWS you can requisition compute power, storage, and other
services–gaining access to a suite of elastic IT infrastructure services as
you demand them. With AWS you have the flexibility to choose whichever
development platform or programming model makes the most sense for the
problems you’re trying to solve. |

|
Speakers Paolo Anedda CRS4 Center for Advanced Studies, Research and Development in Piotr Arlukowicz Marcos Athanasoulis Frank Baetke Global HPC Technology Hewlett Packard Bruce Becker South African National
Grid Gianfranco Bilardi Dept. of Electronics
and Informatics Faculty
of Engineering Padova George Bosilca Innovative
Computing Lab Marian Bubak and Informatics
Institute, Asmterdam THE Charlie Catlett Mathias Dalheimer Fraunhofer Institute for Industrial Mathematics Tim David Centre
for Bioengineering Manoj Devare Dept. of
Electronics, Informatics and Systems Rende,
CS Sudip S. Dosanjh SANDIA
National Labs Skevos Evripidou Department
of Computer Science Jose Fortes Advanced
Computing and Information Systems (ACIS) Lab and Ian Foster and Dept. of
Computer Science The Argonne & Chicago, IL USA Guang Gao Department
of Electrical and Computer Engineering Alfred Geiger T-Systems
Solutions for Research GmbH Wolfgang Gentzsch DEISA Distributed
European Infrastructure for Supercomputing Applications and OGF Vladimir Getov Dror Goldenberg Mellanox Technologies Jean Gonnord CEA - The
French Nuclear Agency Choisel FRANCE Sergei Gorlatch Universität
Münster Institut für
Informatik Münster GERMANY Lucio Grandinetti Dept. of
Electronics, Informatics and Systems Rende,
CS Weiwu Hu Institute
of Computing Technology Christopher Huggins ClusterVision THE Chris Jesshope Informatic Institute, Faculty of Science THE Peter Kacsuk MTA SZTAKI Carl Kesselman Information
Sciences Institute Marina del Rey,
Los Angeles, CA USA Janusz Kowalik University of
Gdansk POLAND Valeria Krzhizhanovskaya St. Petersburg
State Polytechnic University and THE Marcel Kunze Karlsruhe
Institute of Technology Steinbuch
Centre for Computing Tim Lanfear NVIDIA
Ltd Simon Lin Academia Sinica
Grid Computing (ASGC) Thomas Lippert Juelich
Supercomputing Centre Juelich Miron Livny Computer
Sciences Dept. Madison, WI USA Ignacio Llorente Dpt. de
Arquitectura de Computadores y Automática Facultad de
Informática Universidad
Complutense de Madrid Satoshi Matsuoka Dept. of
Mathematical and Computing Sciences Tokyo
Institute of Technology Timothy G. Mattson Intel
Computational Software Laboratory USA Paul Messina Argonne National Laboratory Argonne, IL U.S.A. Ken Miura Center for Grid Research and Development National Leif Nordlund AMD Jean-Pierre Panziera Extreme Computing Division Bull Christian Perez INRIA Raoul Ramos Pollan CCETA-CIEMAT
Computing Center B.B. Prahlada
Rao Programme
SSDG Ulrich Rüde Lehrstuhl
fuer Simulation Universitaet
Erlangen-Nuernberg Erlangen GERMANY Bernhard Schott Platform
Computing Satoshi Sekiguchi Information
Technology Research Institute National
Institute of Advanced Industrial Science and Technology Alex Shafarenko Dept. of
Computer Science Hatfield Mark Silberstein Technion-Israel
Institute of Technology Haifa ISRAEL Leonel Sousa INESC and TU Lisbon,
Lisbon PORTUGAL Domenico Talia Dept. of
Electronics, Informatics and Systems Rende,
CS Dmitry Tkachev T-Platforms Amy Wang Institute
for Theoretical Computer Science Robert Wisniewski Matt Wood Amazon
Web Services Amazon Hongsuk Yi Supercomputing
Center KISTI
Korea Institute of Science and Technology Information Daejeon |
Workshop Agenda
Monday, June 21st
Tuesday, June 22nd
|
Session |
Time |
Speaker/Activity |
|
|
Advances in HPC technology and systems I |
|
|
|
|
S. DOSANJH |
|
|
|
J.P. PANZIERA |
|
|
|
V. GETOV |
|
|
|
S. SEKIGUCHI “Development of High Performance Computing and the Japanese
planning” |
|
|
|
T. LIPPERT |
|
|
|
COFFEE BREAK |
|
|
|
T. MATTSON “The Future of Many Core Processors: a Tale of Two
Processors” |
|
|
|
L. NORDLUND |
|
|
|
S. EVRIPIDOU |
|
|
|
CONCLUDING REMARKS |
|
|
Advances in HPC
technology and systems II |
|
|
|
|
G. BILARDI |
|
|
|
G. BOSILCA |
|
|
|
P. ANEDDA |
|
|
|
COFFEE BREAK |
|
|
|
PANEL DISCUSSION 1: “Challenges and
opportunities in exascale computing” Chair: P. Messina Panelists: S. Dosanjh, J. Gonnord, D.
Goldenberg, T. Lippert, J.P. Panziera,
R. Wisniewski, S. Sekiguchi, S. Matsuoka |
Wednesday, June 23rd
|
Session |
Time |
Speaker/Activity |
|
|
Grid and cloud technology
and systems |
|
|
|
|
M. LIVNY “Distributed Resource Management:
The Problem That Doesn’t Go Away” |
|
|
|
D. TALIA “Service-Oriented Distributed Data Analysis in Grids and
Clouds” |
|
|
|
P. KACSUK “Integrating Service and Desktop
Grids at Middleware and Application Level” |
|
|
|
J. FORTES |
|
|
10:40 – 11:05 |
V. KRZHIZHANOVSKAYA |
|
|
11:05 – 11:35 |
COFFEE BREAK |
|
|
Cloud technology and
systems I |
|
|
|
11:35 – 12:00 |
C. CATLETT “Rethinking
Privacy and Security: How Clouds and Social Networks Change the Rules” |
|
|
12:00 – 12:25 |
I. LLORENTE |
|
|
12:25 – 12:50 |
M. KUNZE “The OpenCirrus Project. Towards an Open-source Cloud Stack” |
|
|
12:50 – 13:00 |
CONCLUDING REMARKS |
|
|
Cloud technology and
systems II |
|
|
|
16:30 – 17:00 |
M. WOOD “Orchestrating
the Cloud: High Performance Elastic Computing” |
|
|
17:00 – 17:25 |
M. DEVARE |
|
|
17:25 – 17:50 |
M. SILBERSTEIN “Mechanisms for
cost-efficient execution of Bags of Tasks in hybrid cloud-grid environments” |
|
|
17:50 – 18:15 |
M. DALHEIMER |
|
|
18:15 – 18:45 |
COFFEE
BREAK |
|
|
18:45 – 20:00 |
PANEL DISCUSSION 2: “State
of the Cloud: Early Lessons Learned With Commercial and Research Cloud
Computing” Chair: C. Catlett Panelists: I. Foster, I. Llorente, M. Dalheimer, M. Kunze |
Thursday, June 24th
|
Session |
Time |
Speaker/Activity |
|
|
Infrastructures, tools,
products, solutions for HPC, grids and clouds |
|
|
|
|
A. WANG “PAIMS: Precision Agriculture
Information Monitoring System” |
|
|
9:25 – 9:50 |
T. MATTSON “Design patterns and the quest
for General Purpose Parallel Programming” |
|
|
|
W. HU |
|
|
10:15 – 10:40 |
L. SOUSA |
|
|
10:40 – 11:05 |
T. LANFEAR |
|
|
|
COFFEE BREAK |
|
|
|
J. KOWALIK “Hybrid Computing for Solving
High Performance Computing Problems” |
|
|
|
P. ARLUKOWICZ |
|
|
|
CONCLUDING REMARKS |
|
|
National and
international HPC, grid and cloud infrastructures and projects |
|
|
|
|
K. MIURA “Cyber Science Infrastructure
in Japan - NAREGI Grid
Middleware Version 1 and Beyond -” |
|
|
|
R. RAMOS POLLAN |
|
|
|
B. BECKER “The
South African National Grid: Blueprint for Sub-Saharan e-Infrastructure” |
|
|
|
B.B. PRAHLADA RAO |
|
|
|
COFFEE BREAK |
|
|
|
S. LIN |
|
|
|
M. BUBAK “PL-Grid: the first functioning National
Grid Initiative in Europe” |
|
|
|
W. GENTZSCH |
|
|
|
H. YI |
|
|
|
CONCLUDING REMARKS |
Friday, June 25th
|
Session |
Time |
Speaker/Activity |
|
|
Challenging applications
of HPC, grids and clouds |
|
|
|
|
C. KESSELMAN |
|
|
|
T. DAVID “System Level Acceleration for
Multi-Scale Modelling in Physiological Systems” |
|
|
|
M. ATHANASOULIS “Building shared
HPC facilities: the Harvard Orchestra experience” |
|
|
|
S. GORLATCH “Towards Scalable Online
Interactive Applications on Grids and Clouds” |
|
|
|
U. RUEDE “Simulation
and Animation of Complex Flows Using 294912 Processor Cores” |
|
|
|
COFFEE BREAK |
|
|
|
A. SHAFARENKO “Asynchronous computing of irregular applications using
the SVPN model and S-Net coordination” |
|
|
|
M. BUBAK “Towards
Collaborative Workbench for Science 2.0 Applications” |
|
|
|
C. PEREZ |
|
|
|
CONCLUDING REMARKS |
CHAIRMEN
Sudip S. Dosanjh
SANDIA National Labs
Wolfgang Gentzsch
DEISA Distributed European
Infrastructure
for Supercomputing
Applications
and
OGF
Satoshi
Matsuoka
Dept. of Mathematical and Computing
Sciences
Tokyo Institute of Technology
Chris Jesshope
Informatic Institute, Faculty
of Science
THE
Ian Foster
and
Dept. of Computer
Science
The
Ian Foster
and
Dept. of Computer
Science
The
U.S.A.
Carl Kesselman
Information Sciences Institute
Marina del Rey, Los Angeles, CA
USA
Guang Gao
Department of Electrical and
Computer Engineering
Miron Livny
Computer Sciences Dept.
Madison, WI
USA
Gerhard Joubert
PANELS
|
Challenges and opportunities in exascale
computing Numerous workshops have identified scientific and engineering
computational grand challenges that could be addressed with exascale computing resources. However, the technology expected to be
available to build affordable exascale systems in
the next decade leads to architectures that will be very difficult to program
and to manage. Will completely new programming models be needed? And new numerical algorithms and
mathematical models? Will a co-design approach that involves application
teams from the beginning of the exascale initiative
make the programming challenges tractable?
The panel participants will debate these issues and other related
topics. Chairman: P. Messina Panelists: S. Dosanjh, J. Gonnord, D.
Goldenberg, T. Lippert, J.P. Panziera,
R. Wisniewski, S. Sekiguchi, S. Matsuoka |
|
State of the Cloud: Early Lessons Learned With
Commercial and Research Cloud Computing This panel will discuss insights gained using cloud
technologies and services for scientific computing. These range from security
to performance, from costs to flexibility. Each panelist
will briefly discuss one or more of these challenges, offering examples of
solutions as well as difficulties related to scientific use of clouds. Chairman: C. Catlett Panelists: |
ABSTRACTS
|
Thinking outside the box: How cloud, grid, and services can make us
smarter Ian Foster Math
& Computer Science Div., Dept of
Computer Science, The Whitehead
observed that "civilization advances by extending the number of
important operations which we can perform without thinking about them."
Thanks to |
|
General-purpose parallel computing
- a matter of scale Chris Jesshope Faculty of Science, Informatics
Institute The question this talk will pose is whether it
possible to achieve the holy grail of general purpose parallel computing. One
of the major pitfalls to this goal is the many and varied approaches to
parallel programming, yet we believe it is possible to provide a generic
virtualisation layer that provides the necessary API to support this variety
of concerns. Another question is whether this interface can be implemented
efficiently across a range of architectures, where by efficiency we mean not
only meeting non-functional constraints on throughput and latency but also
managing constraints on energy dissipated and heat distribution in the target
devices, which is becoming increasingly important. To meet these constraints
it is likely that the target processors will be highly heterogeneous and that
the run-time system will need to support both data-driven scheduling to
manage the asynchrony that comes with this territory as well as to provide
dynamic resource management to allow the overall system to adapt and meet the
these potentially conflicting requirements. We will present the Self-adaptive
virtual processor and describe work on various implementations including in
the ISA of a multi-core, as an interface to FPGA programming and across a
variety of existing conventional and not-so conventional multi-core
platforms. |
|
Dataflow Models for Computation. State of the Art
and Future Scenarios Guang Gao The emerging trend on
multi-core chips is changing the technology landscape of computing system in
the scale that has not been witnessed since the Intel microprocessor chip commissioned
in early 1970s. However, the implication of this technology revolution is
profound: its success can only be ensured if we can successfully
(productively) implement parallel computer architecture on such chips as well
as its associated software technology. We start with a brief
note on the fundamental work on dataflow models of computation in the last
century that goes back to 1960s/ 1970s.
We then comment on the state of the art development of dataflow models
to address the new challenges in parallel architecture and software models
presented by the multi-core chip technology.
Finally, we present some hypotheses on the future scenarios of
advances of dataflow models. |
|
Software Challenges and Approaches for Extreme-Scale
Computing Robert Wisniewski The drive
to exascale contains a series of challenges for
technology. The solutions that will be developed from a technology
perspective are going to lead to a related series of challenges from a system
software perspective. Some of
the prime determiners of the software challenges will include the technology
solutions to meet the power budget and to achieve the requisite
reliability. Also, trends in memory and I/O costs, and their relative
ratios to compute are changing unfavorably.
When investigations began a couple years ago into software for exascale, there was a feeling revolutionary approaches
would be needed in many spaces. As the challenges were examined in
greater detail, there is a growing sense that both because of time
constraints, and achievable evolutionary technology, that while there are
some areas that will require significantly new approaches to achieve exascale, other areas can support exascale
in an evolutionary manner. In the this talk I will lay out the major
technology challenges with likely their solutions, and how that will impact
the system software for exascale. I will then
describe some of the key approaches IBM is taking to address those impacts on
system software. |
|
Hetero – Acceleration the Satoshi Matsuoka Dept. of Mathematical and
Computing Sciences Tokyo Institute of Technology, Since the
first commodity x86 cluster Wigraf achieving paltry
10s~100s Megaflops in 1994, we have experienced several orders of
magnitude boost in performance. However, the first Petaflop
was achieved with the LANL RoadRunner, a Cell-based
"accelerated" cluster, and in 2010 we may see the first
(GP)GPU-based cluster reaching Petaflops. Do such
non-CPU "accelerator” merely push the flops superficially, or are they
fundamental to scaling? Based on experiences from TSUBAME, the first
GPU-accelerated cluster on the Top500, we show that GPUs
not only achieve higher performance but also better scaling, and in fact
their true nature as multithreaded massively-parallel vector processor would
be fundamental for Exascale. Such results are being
reflected onto the design of TSUBAME2.0 and its successors. |
|
Standards-based Peta-scale Systems – Trends, Implementations and
Solutions Frank Baetke Global HPC Technology, Hewlett
Packard, HP’s
HPC product portfolio which has always been based on standards at the
processor, node and interconnect level lead to a successful penetration of
the High Performance Computing market across all application segments.
Specifically the c-Class Blade architecture is now fully established as a
reference for HPC-Systems as the TOP500 list clearly shows. The rich
portfolio of compute, storage and workstation blades comprises a family a
components call the Proliant BL-series
complementing the well-established rack-based Proliant
DL family of nodes. To address additional challenges at the node and systems
level HP recently introduced the Proliant
SL-series. Beyond
acquisition cost, the other major factor is power and cooling
efficiency. This is primarily an issue
of cost for power, but also for the power and thermal density of what can be
managed in a data center. To leverage the economics
of scale established HPC centers as well as
providers of innovative services are evaluating new concepts which have the
potential to make classical data center designs
obsolete. Those new concepts provide significant advantages in terms of
energy efficiency, deployment flexibility and manageability. Examples of this
new approach, often dubbed POD for Performance Optimized Datacenter,
including a concept to scale to multiple PFLOPS at highest energy efficiency
will be shown. Finally
details of a new Peta-scale system to be delivered
later this year will be shown and discussed. |
|
Driving InfiniBand
Technology to Petascale Computing and Beyond Dror Goldenberg Mellanox Technologies, PetaScale
and Exascale systems will span tens-of-thousands of
nodes, all connected together via high-speed connectivity solutions. With the
growing size of clusters and CPU cores per cluster node, the interconnect
needs to provide all of the following features: highest bandwidth, lowest
latency, multi-core linear scaling, flexible communications capabilities,
autonomic handling of data traffics, high reliability and advanced offload
capabilities. InfiniBand has emerged to be the
native choice for PetaScale clusters, and was
chosen to be the connectivity solution for the first Petaflop
system, and is being used for 60% of the world Top100 supercomputers
(according to the TOP500 list). With the capabilities of QDR (40Gb/s) InfiniBand, including adaptive routing, congestion
control, RDMA and quality of service, InfiniBand
shows a strong roadmap towards ExaScale computing
and beyond. The presentation will cover the latest InfiniBand
technology, advanced offloading capabilities, and the plans for InfiniBand EDR solutions. |
|
Status and Challenges of a Dynamic
Provisioning Concept for HPC-Services Alfred Geiger T-Systems
Solutions for Research GmbH The
presentation will first of all describe the state of the art in commercial
HPC-provisioning. Existing concepts are primarily based on shared services
that can be accessed via grid-middleware. However currently we observe a
mismatch between these provisioning concepts and the expectations of
HPC-customers. The request is for a cloud-like model for the provisioning of
temporarily dedicated resources. Treating cloud as a business model rather
than a technology, the service-providers are doing first steps in this
direction. On the other side there are still significant obstacles on the way
to a service that fully meets the customer-requirements. In this contribution
a possible roadmap on the way to dynamic HPC-services will be discussed
together with short-term workarounds for missing pieces of technology.
Furthermore the technology-gaps will be identified. |
|
Clustrx: A New Generation Operating
System Designed for HPC Dmitry Tkachev Research and
Development Director T-Platforms Clustrx
is a new generation HPC OS architected specifically for high performance
computing. Designed by a team of HPC
experts, Clustrx is the first OS in which all the
operating system functionality - the HPC stack and workload management
subsystem - are fully integrated into a single software package. Designed with an innovative, real-time
management and monitoring system, Clustrx
eliminates any limits of scalability and manageability for multi-petaflops clusters and simplifies the shared use of
supercomputing resources for grid environments. Clustrx is the
HPC operating system designed to enable the eventual migration from petascale to exascale. |
|
Managing complex cluster
architectures with Bright Cluster Manager Christopher Huggins ClusterVision, Bright
Cluster Manager makes clusters of any size easy to install, use and manage,
and is the cluster management solution of choice for many universities, research
institutes and companies across the world. In this presentation, ClusterVision will give some examples on how Bright
Cluster Manager makes it easy to install, use, monitor, manage and scale
large and complex cluster infrastructures. |
|
DGSI: Federation of Distributed Compute
Infrastructures Bernhard Schott Platform Computing DGSI (D-Grid
Scheduler Interoperability project) develops the DCI-Federation Protocol enabling
dynamic combination and transparent use of Cloud and Grid resources. The
protocol is open source and technology agnostic and will be implemented in 5
different Grid technologies in the project. Presented implementation examples
are based on Platform Computing Cloud and Grid technology: Platform ISF and
Platform LSF. |
|
Exascale Computing and the Role of Co-design Sudip Dosanjh SANDIA National Labs Achieving
a thousand-fold increase in supercomputing technology to reach exascale computing
(1018 operations per second) in this decade will revolutionize the
way supercomputers are used. Predictive computer simulations will play a
critical role in achieving energy security, developing climate change
mitigation strategies, lowering CO2 emissions and ensuring a safe
and reliable 21st century nuclear stockpile. Scientific discovery,
national competitiveness, homeland security and quality of life issues will
also greatly benefit from the next leap in supercomputing technology. This
dramatic increase in computing power will be driven by a rapid escalation in
the parallelism incorporated in microprocessors. The transition from
massively parallel architectures to hierarchical systems (hundreds of
processor cores per CPU chip) will be as profound and challenging as the
change from vector architectures to massively parallel computers that
occurred in the early 1990’s. Through a collaborative effort between
laboratories and key university and industrial partners, the architectural
bottlenecks that limit supercomputer scalability and performance can be
overcome. In addition, such an effort will help make petascale
computing pervasive by lowering the costs for these systems and dramatically
improving their power efficiency. The U.S. Department of Energy’s strategy for
reaching exascale includes: • Collaborations
with the computer industry to identify gaps • Prioritizing
research based on return on investment and risk assessment • Leveraging
existing industry and government investments and extending technology in
strategic technology focus areas • Building
sustainable infrastructure with broad market support –
Extending beyond natural evolution of
commodity hardware to create new markets –
Creating system building blocks that
offer superior price/performance/programmability at all scales (exascale, departmental, and embedded) • Co-designing
hardware, system software and applications The last element, co-design, is a
particularly important area of emphasis. Applications and system software
will need to change as architectures evolve during the next decade. At the
same time, there is an unprecedented opportunity for the applications and
algorithms community to influence future computer architectures. A new
co-design methodology is needed to make sure that exascale
applications will work effectively on exascale
supercomputers. |
|
Jeanne-Pierre Panziera Extreme Computing Division, Bull,
France As Petaflop-size
systems are currently being deployed, a formidable challenge has been set for the HPC community:
one exaflop within 8-10 years. Relying on technology evolution alone is not
enough to reach this goal. A disruptive approach that encompasses all
aspects of hardware, software and application design is required. |
|
Component-oriented Approaches for Software
Development and Execution in the Extreme-scale Computing Era Vladimir Getov The
complexity of computing at extreme scales is increasing rapidly, now matching
the complexity of the simulations running on them. This complexity arises
from the interplay of variety of factors such as level of parallelism
(systems in this range currently use hundreds of thousands of processing
elements and are envisioned to reach millions of threads of parallelism),
availability of parallelism in algorithms, productivity, design of novel
runtime system software, deep memory hierarchies, heterogeneity, reliability
and resilience, and power consumption, just to name a few. The quest for higher
processing speed has become only one of many challenges when designing novel
high-end computers. While this complexity is qualitatively harder and
multidimensional, addressing successfully the unprecedented conundrum of
challenges in both hardware and software is a key to rapidly unlocking the
potential of extreme-scale computing within the next 10-15 years. In recent
years, component-based technologies have emerged as a modern and promising approach
to software development of complex parallel and distributed applications. The
adoption of software components could increase significantly the development
productivity, but the lack of longer-term experience and the increasing
complexity of the target systems demand more research results in the field.
In particular, the search for the
most appropriate component model and corresponding programming environments
is of high interest and importance. The higher level of complexity as
described above involves a wider range of requirements and resources which
demand dedicated support for dynamic intelligent (non-functional) properties
and flexibility that could be provided in an elegant way by adopting a
component-based approach.
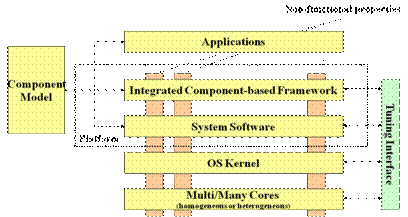
Figure 1: Component-based Development and
Execution Platform Architecture This
paper will present the design methodology of a generic component-based
platform for both applications and system frameworks to have a single,
seamless, “invisible” system image. The block diagram in Figure 1 depicts the
generic architecture of our component-based development and execution
platform. We will
argue that the software development could be simplified by adopting the
component-oriented paradigm, where much better productivity can be achieved
because of the higher level of abstraction. At the same time this approach
enables in a natural way the introduction of autonomic support at runtime
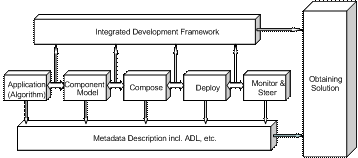
including automatic reconfiguration and tuning. This is illustrated by the
model-to-solution pipeline block diagram presented in Figure 2. The main
functions – compose, deploy, monitor and steer – are being implemented in our
component-based platform.
Figure 2: Component-centric Problem-to-Solution
Pipeline The full
paper will include more details about our initial experience that also cover
some other important aspects of the development and execution cycle such as
validation and dynamic verification. The conclusions include also some ideas
and plans for future research in this area. |
|
Development of High Performance
Computing and the Japanese planning Satoshi Sekiguchi Information Technology Research Institute National Institute of Advanced
Industrial Science and At the
well-known SHIWAKE in November 2009, the Government Revitalisation Unit gave
sentence to freeze on The Next-Generation Supercomputer Project, however it
has been survived under the conditions of engaging more people to enjoy the
benefit of the extreme performance and building national scale infrastructure
to support science, engineering and other businesses. One of the effort just
started to make this happen is to form so-called "HPCI" which
intends to provide a venue to gather computing resources and people around.
As a member of planning HPCI working group, I will introduce an outline of
the discussion and its plan for the future. |
|
PRACE: Thomas Lippert Juelich Supercomputing Centre, Within
the last two years a consortium of 20 European countries has prepared the legal
and technical prerequisites for the establishment of a leadership-class
supercomputing infrastructure in Access to
the infrastructure is provided on the basis of scientific quality through a
pan-European peer review system under the guidance of the scientific steering
committee (SSC) of PRACE. The SSC is a group of leading European peers from a
variety of fields in computational science and engineering. Proposals can be
submitted in form of projects or as programs by communities. In May 2010 a
first early-access call was issued, and the provision of computer time
through PRACE is foreseen commencing in August 2010 by the supercomputer
JUGENE of Research Centre Jülich. Regular provision
will start in November 2010. PRACE's
Tier-0 supercomputing infrastructure will be complemented by national centres
(Tier-1) of the PRACE partners. In the tradition of DEISA, the Tier-1 centres
will provide limited access to national systems for European groups - granted
through national peer review - under the synchronization and governance of
PRACE. |
|
The Future of Many Core
Processors: a Tale of Two Processors Tim Mattson Principal Engineer Intel Labs We all
know by now that many core chips are the future of the microprocessor
industry. They are the only way to
deliver a steady progression of performance improvements in response to These and
other questions are the aim of Intel Lab’s Terascale
research program. As part of this program we envision a sequence of research
chips. 2007’s 80-core terascale processor is the first of these chips.
Recently, we announced our next research chip, the 48 core SCC processor. In this
talk, I will discuss these two research processors and what they tell us
about the future of many core processors. I will also discuss the critical
problem of how to program many core chips. I am a software person so I will
emphasize the applications programmers’ point of view; though I will attempt
to address lower level hardware and software issues as well. |
|
AMD current and future solutions
for HPC Workloads Leif Nordlund Reflections
on the Multicore CPU and the GPGPU architecture
developments, Possible ways to get closer to Heterogeneous computing and Open
standards vs Vendor specific implementations. |
|
The Data-Flow model of Computation
in the Multi-core era Skevos (Paraskevas)
Evripidou Department of Computer Science, The sequential
model of execution has dominated computing since the inception of digital
computers. Research and development on parallel processing was also dominated
by the use of sequential processors with some hardware and/or software
extensions. Proponents of alternative models that are naturally parallel,
such as Data-flow, have been citing the shortcomings and limitations of the
sequential model versus the inherit advantages of the alternative models.
However, the microprocessor designers were able to use the extra transistor
given to them by The
Dynamic Data-flow model is a formal model that can handle concurrency
efficiently in a distributed manner and it can tolerate memory and
synchronization latencies. In this
work we make the case that the Dynamic Data-flow model of execution can be
efficiently combined with the control flow model in order to provide
efficient concurrency control and at the same time fix the limitations of the
control flow that cause the switch to multi-core. The combined model will
benefit from the tolerance to the memory and synchronization latencies of the
data-flow model, thus bypassing the Memory wall. The combined Micro-architecture will be
simpler and more power efficient because they will be no need for the complex
modules that were added to overcome the memory latencies in the control-flow
model. Furthermore, the data-flow scheduling will significantly, reduce the
size of the caches, thus overall reducing the effect of the Power wall. |
|
Gianfranco Bilardi University of
Padova, Italy The
design of algorithms that can run unchanged yet efficiently on a variety of
machines characterized by different degrees of parallelism and communication
capabilities is a highly desirable goal. We propose a framework for
network-obliviousness based on a model of computation where the only
parameter is the problem's input size. Algorithms are then evaluated on a
model with two parameters, capturing parallelism and synchronization
requirements of communication. We show
that optimality in the evaluation model implies near optimality in the
Decomposable BSP model (D-BSP), which deploys logarithmically many parameters
in the number of processors to effectively describe a wide and significant
class of parallel platforms. For a
special class of "wise" network-oblivious algorithms one can
actually establish D-BSP optimality. We
illustrate our framework by providing optimal wise network-oblivious
algorithms for a few key problems, including martix
multiplication and discrete Fouries transform. We also show that some other key problems,
such a broadcast and prefix computation, do not admit optimal
network-oblivious algorithms and characterize exactly how close to optimal
they can come. (This is
joint work with G. Pucci, A. Pietracaprina,
and M. Scquizzato, and F. Silvestri) |
|
Distributed
Dense Numerical Linear Algebra Algorithms on massively parallel heterogeneous
architectures George Bosilca Innovative Computing Lab, In this talk we overlook the drastic changes at
the architectural level over the last few years, and their impact on the
achieved performance for parallel applications. Several approaches to
alleviate this problem have been proposed; unfortunately most of them are
limited to share memory environments. New generation of algorithms and
software are needed to bridge the gap between peak and sustained performance
on massively parallel heterogeneous architectures. Based on a new generic
distributed Direct Acyclic Graph engine for high performance computing (DAGuE), the DPLASMA project is capable of taking
advantage of multicores and accelerators in a
distributed environment. Through three common dense linear algebra
algorithms, namely: Cholesky, LU and QR factorizations,
I will demonstrate from our preliminary results that our DAG-based approach
has the potential to temper this characteristic problem in the
state-of-the-art distributed numerical software on current and emerging
architectures. |
|
Mixing and matching virtual and
physical HPC clusters Gianluigi Zanetti CRS4 Center
for Advanced Studies, Research and Development in High Performance
Computational Clusters are, in general, rather rigid objects that present to
their user a limited number of degrees of freedom related, usually, only to
the specification of the resources requested and to the selection of specific
applications and libraries. While in
standard production environments this is reasonable and actually desirable,
it can become an hindrance when one needs a dynamic and flexible
computational environment, for instance for experiments and evaluation, where
very different computational approaches, e.g., map-reduce, standard parallel
jobs and virtual HPC clusters need to coexist on the same physical facility.
We describe a new approach in the management of small to medium,
general-purposes clusters based on a flexible High Performance Computing
(HPC) software platform capable of partition physical clusters, allocate
computing nodes and create and deploy virtual HPC clusters. |
|
Distributed Resource Management:
The Problem That Doesn’t Go Away Miron Livny Computer Sciences Dept., After
more than 30 years of distributed computing research and more than a decade
of grid computing, operators and users are still struggling with how to
allocate (some refer to it as provision) resources in a distributed
environment. Community owned overly
job managers (some refer to them as glide-ins or pilot jobs) are growing in
popularity as a partial solution to this problem. We will report on our
recent work on using such overlays to manage the allocation of CPUs and will
discuss our plans to add support for allocation of storage resources. |
|
Service-Oriented Distributed Data
Analysis in Grids and Clouds Domenico Talia Dept. of Electronics, Informatics
and Systems Today a
major challenge in data mining and knowledge discovery is the analysis of
distributed data, information and knowledge sources. New data analysis and
knowledge discovery systems should be able to mine distributed and highly
heterogeneous data found on Internet, Grids and Clouds. The Service-Oriented
paradigm provides a viable approach to implement distributed knowledge
discovery systems and applications that run on dispersed computers and
analyse distributed data sets. This talk
introduces a general framework for service-oriented knowledge discovery and
presents some experiments developed in the new service-oriented version of
the Knowledge Grid framework. |
|
Integrating service and desktop
grids at middleware and application level Peter Kacsuk MTA SZTAKI, Current
Grid systems can be divided into two main categories: service grids (SG) and desktop
grids (DG). Service grids are typically organized from managed clusters and
provide a 24/7 service for a large number of users who can submit their
applications into the grid. The service grid middleware is quite complex and
hence relatively few managed clusters take the responsibility of providing
grid services. As a result the number of processors in SGs
is moderate typically in the range of 1.000-50.000. Even the largest SG
system, EGEE has collected less than 200.000 computers. Desktop
grids are collecting large number of volunteer desktop machines to exploit
their spare cycles. These desktops have no Comparing
the price/performance ratio of SGs and DGs the creation and maintenance of DGs
is much cheaper than the one of SGs. Therefore it
would be most economical if the compute-intensive bag-of-task applications
could be transferred from the expensive SG systems into the cheap DG systems
and executed there. On the other hand when an SG system is underloaded its resources could execute WUs coming from a DG system and in this way existing SG
systems could support the solution of grand-challenge scientific
applications. The
recognition of these mutual advantages of integrating SGs
and DGs led to the initiation of the EDGeS (Enabling Desktop Grids for e-Science) EU project
that was launched in January 2008 with the objective of integrating these two
kinds of grid systems into a joint infrastructure in order to merge their
advantages into one system. The EDGeS project
integrated gLite-based service grids with BOINC and
XtremWeb DG systems. To make
these systems interoperate there are two main options. At the level of the
middleware EDGeS has created the 3G Bridge ( The
second option for grid users to exploit both SGs
and DGs can be achieved at the application level.
Particularly, in the case of complex workflow applications when bag-of-task
jobs, data-intensive jobs, MPI jobs and others are used in a mixed way, a
high-level grid portal can help the users to distribute the jobs of the
workflow to the most appropriate SG or DG systems. This has also been solved
in EDGeS in the framework of P-GRADE portal. All these
experiences will be explained in detail in the talk. At the end, some future
plans of the EDGI project will be shown how to support QoS
requirements even in the DG part of the integrated SG-DG infrastructure by
supporting DG systems with some dedicated local academic clouds. |
|
José Fortes Advanced Computing and Information
Systems (ACIS) Lab and NSF Center for
Autonomic Computing (CAC) This talk
will make the case for, discuss requirements and challenges of, and introduce
possible technologies and applications for cross-cloud computing. |
|
Dynamic
workload balancing with user-level scheduling for parallel applications on
heterogeneous Grid resources Valeria Krzhizhanovskaya and We
present a hybrid resource management environment, operating on both application
and system levels, developed for minimizing the execution time of parallel
applications on heterogeneous Grid resources. The system is based on the
Adaptive WorkLoad Balancing algorithm (AWLB)
incorporated into the DIANE User-Level Scheduling (ULS) environment. The AWLB
ensures optimal workload distribution based on the discovered application
requirements and measured resource parameters. The ULS maintains the
user-level resource pool, enables resource selection and controls the
execution. We present the results of performance comparison of default
self-scheduling used in DIANE with AWLB-based scheduling, evaluate dynamic
resource pool and resource selection mechanisms, and examine dependencies of
application performance on aggregate characteristics of selected resources
and application profile. |
|
Rethinking Privacy and Security:
How Clouds and Social Networks Change the Rules Charlie Catlett Many of
today's concepts, architectures, and policies related to privacy and security
are based on the traditional information infrastructure in which data and
assets are created, controlled, and contained within a protected perimeter.
Concepts such as "control" and "containment" are
quite different in today's context of interconnected social networks,
powerful multi-sensor mobile phones, ubiquitous wireless broadband, and
networks of cloud services. This presentation will discuss examples of
new capabilities exposing flaws in traditional privacy and security
assumptions, suggesting areas of computer science research and development
that are needed to address these new challenges. |
|
Innovations in Cloud Computing
Architectures Ignacio Llorente Dpt. de Arquitectura de Computadores y
Automática, Facultad de Informática Universidad Complutense de Madrid Madrid, SPAIN The aim
of the presentation is to describe the innovations in cloud management
brought by the OpenNebula Cloud Toolkit. This
widely used open-source Cloud manager fits into existing data centers to build private, public and hybrid
Infrastructure-as-a-Service (IaaS) Clouds. Most of
its innovative features have been developed to address requirements from
business use cases in RESERVOIR, flagship of European research initiatives in
virtualized infrastructures and cloud computing. The innovations comprise
support for elastic multi-tier services; flexible and scalable back-end
for virtualization, storage and networking management; and support for Cloud
federation and interoperability. The presentation ends with an introduction
of the community and ecosystem that are evolving around OpenNebula
and the new European project on cloud computing infrastructures that are
using this innovative cloud technology. |
|
The OpenCirrus Project. Towards an Open-source Cloud Stack Marcel Kunze Karlsruhe Institute of Technology, Steinbuch Centre for Computing OpenCirrus is a collaboration of industrial and academic organizations: HP,
Intel, Yahoo!, CMU, ETRI, IDA Singapore, KIT, MIMOS, RAS and UIUC. OpenCirrus is an open cloud-computing research testbed designed to support research into the design,
provisioning, and management of services at a global, multi-datacenter scale. The open nature of the testbed aims to encourage research into all aspects of
service and datacenter management. In addition, the
hope is to foster a collaborative community around the testbed,
providing ways to share tools, lessons and best practices, and ways to
benchmark and compare alternative approaches to service management at datacenter scale. The specific research interests of KIT
are in the field of HPC as a Service (HPCaaS) and
Big Data as a Service (BDaaS). |
|
Orchestrating the Cloud: High
Performance Elastic Computing Matt Wood Amazon
Web Services, Constraints
are everywhere when working with high throughput tools, be they data mining,
indexing, machine learning, financial analysis or complex scientific
simulations. As scale increases so network, disk I/O, CPU performance and
utilization all become larger and larger barriers to to
actually getting work done. This talk
introduces the use of elastic, scalable cloud approaches as a set of
productivity tools for constrained, highly flexible domains. We’ll explore
how Cloud Computing can play a central part in the orchestration, management
and monitoring of scalable computation at petabyte
scale. Over the course of the session, we’ll aim to cover: + The
productivity tax of web scale applications + Hard
constraints of big data: maintaining availability at scale + Architectures
and models for high throughput systems +
Addressing data as a programmable resource +
Orchestrating cloud architectures +
Managing data sets and workflows +
Map/reduce for elastic infrastructures. |
|
A Prototype implementation of
Desktop Clouds Manoj
Devare, Mehdi Sheikhalishai, Lucio Grandinetti Department
of Electronics, Informatics and Systems, The cloud computing is a popular paradigm, for
serving the software, platform and infrastructure as a service to the
customer. It has been observed, seldom the highest capacity of the personal
computers (PC) are utilized. This work provides the virtual infrastructure
manager and scheduling framework to leverage the idle resource(s) of PCs. VirtualBox hypervisor is used
as the best suited virtualization technology for this work. In this talk we will discuss this novel architecture
and the scheduling approach to launch a computation abstracted as a virtual
machine or a virtual cluster using full virtualization approach. The
scheduling framework balances both requirements of resource provider (PC
owners) i.e. the permission of the PC owner to be taken into account and user
of the cloud system who expects the best performance during the whole
session. One can submit lease requirement to the scheduler
e.g. for running HPC applications. It is a bit tricky to work in such a
non-dedicated heterogeneous environment, for yielding the power of the idle
resources of Computers. |
|
Mechanisms
for cost-efficient execution of Bags of Tasks in hybrid cloud-grid
environments Mark Silberstein Technion-Israel Institute of Technology Pay-for-use
execution environments (clouds) allow for substantial cost savings when
coping with unexpected surges in computing demand, eliminating the need to
over-provision the required capacity. Their cost effectiveness for
scientific computing, however, appears to be far lower, in particular
if one already has access to established grids and clusters. To enable the
grid/cloud hybrids, the current state-of-the-art in the middleware systems
(Condor/Sun Grid Engine) has been to allow demand-driven extension of the local
resources into the cloud when the former are insufficient to accommodate the
load. In this
talk we suggest an alternative, more cost-effective way to use grids
and clouds together, which appears to be exactly the opposite of the common
"rent-when-insuffcient-resources"
approach. The core observation is that the cloud resources exhibit lower
failure rate as opposed to the shared ones in the grid, and can be employed
only when the resource reliability becomes critical: when the bulk of the Bag
of Tasks has been already completed, and there are only a few tasks left. We
argue that the middleware requires a number of policy-driven runtime
mechanisms, with the task replication being the most important one. On the
example of the GridBot system we demonstrate that
these mechanisms combined with the proper policy enable up to an order of
magnitude savings in costs and twice as faster execution of short and long BoTs on a number of production grids and Amazon EC2,
versus the standard demand-driven approach. |
|
Cloud
Computing and Mathias Dalheimer Fraunhofer Institute for Industrial Cloud
computing provides a new model for accessing compute and storage capacity.
Companies have to pay for operational expenses (OpEx)
only, no capital expenses (CapEx) will be billed.
This provides an attractive approach for most enterprises. On the other hand,
the integration of external resources in enterprise IT environments holds
some challenges. The talk demonstrates which HPC applications can take
advantage of cloud computing offers and outlines the problems we experienced. |
|
PAIMS: Precision Agriculture
Information Monitoring System Amy Wang Institute for Theoretical Computer
Science, This talk
will introduce some of the considerations taken and results of research
conducted for the large scale wireless sensor network system for agriculture
information monitoring applications. The sensor networks and crucial national
requirements for real-time farmland and crop information monitoring systems
will be introduced first. Second, a Precision Agriculture Information
Monitoring System (PAIMS) will be introduced, which is designed for the
long-term monitoring of large scale farmland. The PAIMS system consists of a
two-tiered sensor network and an information service platform. The sensor
network contains a large number of energy-constrained low tier nodes (LNs) to capture and report information from their
designated vicinity. Then, some powerful gateways in the high tier to
organize the LNs to form clusters which report the
aggregated information to the Internet. The information service platform logs
information from the sensor network and provides value-created services to
the user. After giving an overview of
the PAIMS system, selected research results in PAIMS will be introduced in
detail, including, to name a few, a Multi-hop Joint Scheduling algorithm and a
Distributed Dynamic Load balancing algorithm. The hardware and system
implementation issues of PAIMS will also be introduced. Finally, we will
discuss possible directions of future research. |
|
Design Patterns and the quest for
General Purpose Parallel Programming Tim Mattson Principal Engineer Intel Labs In a many
core world, all software should be parallel software. It’s hard enough
making our scientific applications parallel, but how are we going to
parallelize the large mass of general purpose software? In this
talk, I suggest that software frameworks informed by design patterns and
deployed on top of industry standard hardware abstraction layers (such as OpenCL) could solve this problem. My goal, however,
is not to present a tidy solution to the problem. We have too many
solutions chasing this problem already. My goal is to establish a
position and then engage in a vigorous debate leading to objective analysis
and in the long run, a solution to this problem that actually works. |
|
A Multicore
Processor Designed For Petaflops Computation Weiwu Hu Institute of Computing Technology Chinese Godson-3
is a multicore processor designed by |
|
Efficient Execution on
Heterogeneous Systems Leonel Sousa INESC-ID/IST, TU Lisbon Modern
parallel and distributed systems rely on multi-core processors for improving
performance. Furthermore, modern systems are configured with processors of
different characteristics such as general-purpose multi-core processors and
accelerators. While such systems provide a better match between the application
requirements and the hardware provided, the efficient execution of
applications on heterogeneous systems is currently an open issue. On the one
hand, the user wants to write a single version of the program while, on the
other hand, in order to exploit the available performance it is needed to
tune the application to the target architecture. Common
programming models that allow the user to program once and execute on
different architectures have recently been developed. Examples of such models
include Rapidmind (recently Intel is integrating it
with their own Ct programming model) and the OpenCL
standard. Nevertheless, previous works have shown that there is a
considerable penalty in using such an approach as the application is not
tuned to the different target architectures in heterogeneous systems. In this
work we take a different approach and exploit the execution of multiple tuned
versions of the same application on the heterogeneous system. While at this
point we rely on hand-tuned versions, in the future dynamic compilation
techniques may help tuning the code. The issue though is the coordination of
the execution of these different tuned versions. As such, we focus on a
high-level scheduler that coordinates the execution of these versions on the
heterogeneous system. To prove
the proposed concept we selected a database workload as target application.
We provide versions of the basic database algorithms, tuned for GPUs using CUDA, for Cell/BE using the Cell SDK and for
general-purpose multi-cores using OpenMP. The
application uses basic algorithms to process queries from the standard
Decision-Support System (DSS) benchmark TPC-H. The scheduler distributes the
work among the different processors and assigns the corresponding tuned
versions of the code for each algorithm. |
|
High-Performance Computing with
NVIDIA Tesla GPU Tim Lanfear NVIDIA Ltd, GPU computing
is the use of a GPU (graphics processing unit) for general purpose scientific
and engineering computing. The architecture of a GPU matches well to many
scientific computing algorithms where the same operation is applied to every
element of a large data set. Many algorithms have been ported to GPUs and benefited from significant increases in
performance when compared with implementations on traditional
microprocessors. NVIDIA’s next generation of Tesla GPUs
using the Fermi architecture offer all the features needed for deployment of GPUs in large-scale HPC systems, including enhanced
double-precision performance, hierarchical caches, ECC protection of data
on-chip and off-chip, and high memory bandwidth. |
|
Hybrid Computing for Solving High
Performance Computing Problems Janusz Kowalik
and Piotr Arlukowicz Hybrid
computing is a combination of sequential and highly parallel computing.Sequential computing is executed by CPU and
parallel by GPU. This binomial mode of computation is becoming a practical
tool for solving HPC problems. The paper presents the key architectural
features of GPU and discusses performance issues. A large linear algebra example
illustrates the benefits of the GPU acceleration. |
|
An Introduction to CUDA Programming: A
Tutorial Piotr Arlukowicz
and Janusz Kowalik The tutorial
is about the basics of NVIDIA accelerators architecture and the methods of
programming with CUDA technology. It will deal with internal hardware
structures, and will cover some simple, but low-level C code examples
illustrating fundamental techniques used to obtain the processing speed and
efficiency. This tutorial is intended for persons having programming
experience but without CUDA programming expertise. |
|
Cyber
Science Infrastructure in
Japan - NAREGI Grid Middleware Version 1 and Beyond - Kenichi
Miura, Ph.D Center for Grid Research
and Development National The
National Research Grid Initiative (NAREGI) Project was a research and
development on the grid middleware from FY2003 to FY2007 under the auspices
of the Ministry of Education, Culture, Sports, Science and Technology (MEXT).
Now we are in the phase of deploying the NAREGI Version 1 grid middleware to
the nine university-based national supercomputer centers
and some domain specific research institutes such as the Institute for
Molecular Science (IMS), National High Energy Accelerator Research
Organization (KEK) and the National Astronomical Observatory (NAOJ). The
National Institute of Informatics (NII) already initiated the realization of
the computational research and educational environment called “Cyber Science
Infrastructure” in 2005, based on the national academic backbone network,
called SINET3, and the NAREGI grid middleware is a key component in it. As a
follow-on project to NAREGI, the “RENKEI (Resources Linkages for e-Science)
Project” also started in September 2008. In this project, a new light-weight
grid middleware and software tools are being developed in order to provide
the connection between the NAREGI Grid environment and wider research
communities. In particular, technology for the flexible and seamless accesses
between the national computing center level and the
departmental/laboratory level resources, such as computers, storage and
databases is one of the key objectives. Also, this newly developed grid
environment will be made interoperable with the major international grids
along the line of OGF standardization activities. http://www.naregi.org/index_e.html Kenichi
Miura is a professor in High-end Computing at the National Institute of
Informatics (NII) and also the director of the Center
for Grid Research and Development. He was the former project leader of the
Japanese National Research Grid Initiative (NAREGI) project. He is also a
fellow of Fujitsu Laboratories, Ltd and a visiting researcher of RIKEN in
conjunction with the Next Generation Supercomputer Project. Dr, Miura is a
member of the Engineering Academy of Japan. Dr. Miura
received his Ph.D. degree in Computer Science from the |
|
The
road to sustainable eInfrastructures in Latin
America Raoul Ramos Pollan CCETA-CIEMAT Computing The EELA
and EELA2 projects constitute the first effort to build a continental eInfrastructure in |
|
The South African National Grid :
Blueprint for Sub-Saharan e-Infrastructure Bruce Becker South African National Grid The Sub-Saharan
Region of Africa has been isolated geographically and technologically from
the rapid advances in e-Science due in part to a lack of infrastructures,
such as high-performance networks, computing resources and skilled
technicians. However, this situation is evolving very rapidly, due to the
improved network connectivity of the region, and the significant investment
made in |
|
GARUDA: Indian National Grid
Computing Initiative Dr. B.B. Prahlada
Rao Programme SSDG, Nations are
realizing the importance of new e-infrastructures to enable scientific
progress and research competitiveness. Making grid / cloud infrastructures
available to the research community is crucial and is important to the
researchers and the development teams in |
|
Building e-Science and HPC
Collaboration in Simon Lin Academia Sinica
Grid Computing (ASGC) Data
deluge drives the evolution of new science paradigm and the Grid-based
distributed computing infrastructure such as WLCG and EGEE. Starting from WLCG since 2002, with the
support of Asia Pacific Regional Operation Centre (APROC) running by the only
WLCG Tier-1 Center in Asia – ASGC, Grid resource centers has growth from 6 sites in 2005 to 30 sites in
2010 and contributing to 16 virtual organizations, CPU utilization increases
over 571 times in the past 5 years. |
|
PL-Grid: the first functioning National
Grid Initiative in Europe Marian Bubak ICS/ACC Cyfronet
AGH Informatics Institute, Universiteit van
Amsterdam, The Netherlands The goal of
the PL-Grid Project [1] is to provide the Polish scientific community with an
IT platform based on Grid computer clusters, enabling e-science research in
various fields. This infrastructure will be both compatible and interoperable
with existing European and worldwide Grid. PL-Grid
aims at significantly extending the amount of computing resources provided to
the Polish scientific community (by approximately 215 TFlops
of computing power and 2500 TB of storage capacity) and constructing a Grid
system that will facilitate effective and innovative use of the available
resources. PL-Grid will draw upon the experience of European initiatives,
such as EGEE and DEISA, the scientific results attained by individual
partners and the outcome of R&D activities carried out within the
project. An PL-Grid
will engage in collaboration with end users from its inception, providing
training services for approximately 700 participants and undertaking joint
development activities on new applications and domain-specific services. The
emergence of the PL-Grid framework is consistent with European Commission
policies which actively encourage development and integration of computing
Grids. On Acknowledgements: The
Project is co-funded by the European Regional Development Fund as part of the
Innovative Economy program under contract POIG.02.03.00-00-007/08-00. References [1]
PL-Grid website: http://www.plgrid.pl/en |
|
DEISA and the European HPC
Ecosystem Wolfgang Gentzsch The DEISA Project and Open
Grid Over the
last decade, the European HPC scenario has changed dramatically, from a
few scattered national HPC centers 10 years ago to
an HPC ecosystem of
interoperating and collaborating HPC centers today
serving virtual organizations
and communities tackling their
grand-challenge big-science applications.
The ever increasing complexity of science applications, increasing
demands of computational scientists, and the challenge of building
and deploying the fastest and most expensive HPC systems has forced our
HPC community to develop and implement one sound and joined HPC ecosystem
for This
widely agree ecosystem can best be described by a three-layer HPC pyramid
consisting, at its bottom level, of regional HPC centers
and national
grid computing resources, and at its top level of the most powerful
HPC systems represented by the PRACE initiative. Central to this HPC
ecosystem is DEISA, the Distributed European Infrastructure for Supercomputing
Applications, connecting 15 of the most powerful supercomputer
centers in resources,
identity management, security, and interoperability and standardisation.
In addition, we present high performance computing applications
on the DEISA infrastructure, as represented by the DEISA Extreme
Computing Initiative (DECI) or more recently, by so-called virtual communities
and their scientific endeavours. |
|
HPC Infrastructure and Activity in
Hongsuk Yi KISTI (Korea Institute of Science
and Technology Information) The |
|
The
Grid as Infrastructure for Sharing BioMedical
Information: The Biomedical Informatics Research Network Carl Kesselman Information Sciences Institute, Marina del Rey, Los Angeles, CA, USA Increasingly, translational research and clinical
practice is impeded by the ability to exchange diverse health related information
between collaborating parties. The issue of data sharing in a health context
is complicated by issues of privacy, heterogeneity of the underlying data
types, diverse semantic models, and the fundamentally complex nature of the
health-care ecosystem. In this talk, I will discuss the ramifications of the
underlying systems complexity of the health care system and how Grids and the
associated concept of virtual organizations can provide solutions to the
problems that result from this complexity. I will illustrate how Grid
infrastructure can be applied within a number of clinical and research
applications, including as part of the Biomedical Informatics Research
Network (BIRN), a national scale medical information sharing infrastructure
supported by the NIH. |
|
System Level Acceleration for
Multi-Scale Modelling in Physiological Systems Tim David Centre
for Bioengineering, Computational
models of human physiology require the integration of a number of physical
scales from the nano-cellular to the human frame.
Currently these models have relied on a single architecture on which to solve
the resulting equation sets. In order to understand the important functions
and relationships that make up the natural working human body, as well as
pathological environments, scientists and engineers are required to solve
integrated equations sets whose forms are mostly radically different. These
are different essentially because of the variation in length scales that are
required to be resolved. For instance a cell lining the human artery is of
the order of a few hundred nanometers, where the
artery itself can be of the order of a metre. Several different
computer architectures have appeared over the past twenty years, from the
original Cray vector pipeline through the distributed memory systems of the Meiko computing surface to the new partially-mixed
architectures of the IBM p-575 series and finally the massively parallel Blue
Gene system. It is not difficult to understand how certain problems have
evolved (and optimized) for certain architectures. With the present
requirement for the solution multiple-scales problems it is pertinent to
start to search for a more integrated solution algorithm that takes the best
of both worlds. A new
computing paradigm - the System Level Accelerator - can be employed to solve
complex multi-scale problems. The
presentation will show how we have mapped the cerebrovasculature
on a p-575 SMP supercomputer, whilst simulating the autoregulation
network via large binary trees by mapping on a fully distributed computing
system, such as a Blue Gene supercomputer. We will
present load balancing data as well as full solutions for fluid flow (blood)
throughout the entire cerebro-vasculature. a
problem of this scale in unprecedented in computational physiology and
bioengineering. |
|
Towards
Scalable Online Interactive Applications on Grids and Clouds Sergei Gorlatch We study
a class of Internet-based environments with high interactivity of multiple
users and soft real-time requirements. Challenging
examples of such applications are massively multi-player online games (MMOG)
and high-performance e-Learning and training systems. We
describe the Real-Time Framework (RTF) developed at the |
|
Simulation
and Animation of Complex Flows Using 294912 Processor Cores U. Ruede, J. Götz, K. Iglberger, C.
Feichtinger, S. Donath Lehrstuhl
fuer Simulation, Universitaet Erlangen-Nuernberg We employ
the Jugene system at Jülich
with almost 300,000 cores to simulate fluids with suspended particles based
on a detailed microscopic fluid-structure-interaction. The largest runs
involve more than a hundred billion fluid cells, resulting in one of the
largest CFD computations to date. The simulations use novel parallel
algorithms for the handling of moving obstacles that are fully resolved as
individual geometric objects. With
these techniques, we can study flow effects resulting from particles of
arbitrary, non-spherical shape. The efficient parallelization of the
rigid-body dynamics algorithm and the two-way fluid-structure-interaction are
major challenges, since they require a parallel collision detection and
parallel collision response algorithms. We will present simulations with up
to 264 million particulate objects that move and interact with the flow. Despite
its complexity, the overall simulation still runs at a parallel efficiency of
better than 95%. The talk will focus on the design and analysis of the
algorithms and their implementation for various supercomputer architectures,
including the Blue Gene/P. Additionally, we will present experiments on
heterogeneous architectures using GPUs as
accelerator hardware. |
|
Asynchronous computing of
irregular applications using the SVPN model and S-Net coordination Alex Shafarenko1 and Alexei Kudryavtsev2 1) 2) Institute of Theoretical and
Applied Mechanics, This talk
will address a new design representation for irregular distributed
applications: a Spinal Vector Petri Net (SVPN). SVPN is a
vector of identical graphs which have processing functions at the nodes and
which have messages floating along the edges. It is a distant relative of
Coloured Petri Nets in that it reveals the synchronisation structure of an
asynchronous application and can be used for analysis of its behaviour. SVPN
can naturally support irregular applications, such as Particles-in-Cells
simulations of plasma and molecular dynamics, as message-driven processes,
without the programmer being aware of any subtle concurrency issues. Our main
contribution to knowledge is a demonstration that the mapping of SVPN to the
coordination language S-Net is nearly mechanical, which makes it possible, at
least in principle, to write asynchronous, irregular applications directly in
S-Net and utilise its advance support for software engineering. |
|
Towards Collaborative Workbench
for Science 2.0 Applications Marian Bubak ICS/ACC Cyfronet
AGH Informatics Institute, Universiteit van
Amsterdam, The Netherlands This talk
presents investigations aimed at building an
universal problem solving environment which facilitates programming and
execution of complex Science 2.0 applications running on distributed
e-infrastructures. Such
applications involve experimentation and exploratory programming, with multiple
steps which are not known in advance and often are selected ad-hoc depending
on obtained results. This
research is based on experience gathered during development of the ViroLab Virtual Laboratory [1, 2, 3], the APPEA runtime
environment for banking and media application in GREDIA project [4, 5], the GridSpace environment [6] for running in-silico experiments, on user requirements analysis during
the initial phase of PL-Grid project [7], as well as on a concept of the
Common Information Space which is developed in the framework of the UrbanFlood Project [8]. In this project,
applications have the form of reusable
digital artifacts (such as scripts) that glue
together loosely coupled components (plug ins) accessible via standardized
programming interfaces and CIS enable distributed deployment of independent,
loosely coupled information spaces, responsible for processing of data from
separate sensor networks. The
workbench provide support for sharing and reuse of applications components,
such as scripts, code snippets and whole experiments. It will be enabled to
publish experiment as web application and obtained result data will be a
subject to store, publish and share. As opposed to existing virtual
laboratories, the workbench will support exploratory experimentation
programming paradigm and multifaceted collaboration by sharing software, data
and ready-to-use web applications. Acknowledgements:
This work is partially supported by the EU UrbanFlood
and
PL-Grid projects. References [1] M. Bubak, M. Malawski, T. Gubala, M. Kasztelnik, P. Nowakowski, D. Harezlak, T. Bartynski, J. Kocot, E. Ciepiela, W. Funika, D. Krol, B. Balis, M. Assel, and A. Tirado
Ramos. Virtual laboratory for collaborative applications. In M. Cannataro, editor, Handbook of Research on Computational GridTechnologies for Life Sciences, Biomedicine and
Healthcare, chapter XXVII, pages 531-551. IGI Global, 2009. [2] P.M.A
Sloot, Peter V. Coveney,
G. Ertayalan, V. Mueller, C.A. Boucher, and M. Bubak: HIV decision Support: from Molecule to Man.
Philosophical Transactions ofthe Royal Society A, vol 367, pp 2691 - 2703, 2009,
doi:10.1098/rsta.2009.0043. [3] ViroLab Virtual Laboratory: http://virolab.cyfronet.pl [4] D. Harezlak, P. Nowakowski, M. Bubak. Appea: A Framework for
Design and Implementation of Business Applications on the Grid, Proceedings
of Computational Science - ICCS 2008 , 8th International Conference
Krakow, Poland, June 2008, volume III, LNCS 5103, Springer, 2008 [5]
http://www.gredia.eu [6] GridSpace http://gs.cyfronet.pl [7] PL-Grid
- Polish Infrastructure for Information Science Support in the European
Research Space: http://www.plgrid.pl/en [8] UrbanFlood
EU Project: http://urbanflood.eu/ |
|
On High Performance Software Component
Models Christian Perez Software
component models appear as a solution to handle the complexity and the
evolution of applications. It turns out to be a powerful abstraction
mechanism for dealing with parallel and heterogeneous machines as it enable
the structure of an application to be manipulated, and hence specialized.
Challenges include the understanding and the definition of an adequate
abstraction level of application description so as to enable machine specific
optimization. This talk
will overview some works we have done in increasing the level of abstraction
of component models for HPC applications, including component level
extensions such as parallel components, or assembly level extensions such as
dynamic assembly. It will also discuss the usage of model transformation
techniques as a framework to optimize applications. |